目前的情况:有1台机器6张3090(单机多卡),但是实验室共用,可能不同的卡剩余内存的情况不一样,所以想要能指定1张卡或几张卡进行训练。
选择:DataParallel or DistributedDataParallel?
DataParalllel虽然简单,但是它的负载是不平均的,可以看这篇文章Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups的解释,简短来说,DataParallel不涉及同步,只是将多个GPU计算得来的梯度汇总到一个GPU进行更新。对于大模型使用DistributedDataParallel效率更高,DistributedDataParallel设置了同步,真正实现了并行。需要注意的是,不管是哪个函数,自定义的model一定要在forward上重载,如果有几个forward或者forward参数不能对标,会出问题。比如有参数在__init__中,但在forward中使用,那这些参数就没办法并行放入,会导致数据和模型分离,不在同一个GPU上,会报错!。所有在forward中使用的参数必须直接传入,这样才能直接用这两个函数。接下来介绍DistributedDataParallel的用法。
DistributedDataParallel的用法
🔗:A Comprehensive Tutorial to Pytorch DistributedDataParallel
代码可参考🔗:tf-torch-template
DistributedDataParallel将模型复制到K个GPU上,把数据拆到K个GPU上(数据并行)。可以做的前提是模型在一个GPU上是放得下的。
Setup the process group
process group:有K个GPU就对应K个进程rank: 每个进程对应的id,从0到K-1,rank=0是master nodeworld size:总共的进程数/GPU数
import torch.distributed as dist def setup(rank, world_size): os.environ['MASTER_ADDR'] = 'localhost' # or 127.0.0.1 os.environ['MASTER_PORT'] = '12355' # nccl is the most recommand backend dist.init_process_group("nccl", rank=rank, world_size=world_size)Split the dataloader
dataloader需要拆分数据到K个GPU上并且保证他们不会有overlap。可以用
DistributedSampler实现。from torch.utils.data.distributed import DistributedSampler # pin_memory默认是false,这里不写也行,感觉这个参数跟我没什么关系 def prepare(rank, world_size, batch_size=32, pin_memory=False,num_workers=0): dataset = Your_Dataset() sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank, shuffle=False, drop_last=False) dataloader = DataLoader(dataset, batch_size=batch_size, pin_memory=pin_memory, num_workers=num_workers, drop_last=False, shuffle=False, sampler=sampler) return dataloaderWrap the model with DDP
from torch.nn.parallel import DistributedDataParallel as DDP def main(rank, world_size): # setup the process groups setup(rank, world_size) # prepare the dataloader dataloader = prepare(rank, world_size) # instantiate the model(it's your own model) and move it to the right device model = Model().to(rank) # wrap the model with DDP # device_ids tell DDP where is your model # output_device tells DDP where to output, in our case, it is rank # find_unused_parameters=True instructs DDP to find unused output of the forward() function of any module in the model model = DDP(model, device_ids=[rank], output_device=rank, find_unused_parameters=True)训练结束后,如果我们想要从checkpoint中加载我们的模型,我们需要加上
model.module。下面这段代码可以自动的把这个prefix去掉,从model.module.xxx到model.xxx:# in case we load a DDP model checkpoint to a non-DDP model model_dict = OrderedDict() pattern = re.compile('module.') for k,v in state_dict.items(): if re.search("module", k): model_dict[re.sub(pattern, '', k)] = v else: model_dict = state_dict model.load_state_dict(model_dict)Train/test our model
optimizer = Your_Optimizer() loss_fn = Your_Loss() for epoch in epochs: # if we are using DistributedSampler, we have to tell it which epoch this is dataloader.sampler.set_epoch(epoch) for step, x in enumerate(dataloader): optimizer.zero_grad(set_to_none=True) pred = model(x) label = x['label'] loss = loss_fn(pred, label) loss.backward() optimizer.step() cleanup() import torch.multiprocessing as mp if __name__ == '__main__': # suppose we have 3 gpus world_size = 3 mp.spawn( main, args=(world_size), nprocs=world_size )如果想要指定GPU而不是顺序用GPU,需要在torch import之前设定好环境变量:
import os os.environ['CUDA_VISIBLE_DEVICES'] = '4, 5, 6, 7'
上述是一个很详细的解释。但是把它用到项目里如何去组织?可以参考:tf-torch-template。我在这个框架上进行了修改,满足指定GPU的功能。具体修改如下:
在
config.yaml上指定device_ids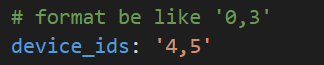
在
run.py的入口处修改world_size
在
run_fn中指定GPUdevice的格式类似’cuda:2’,将device传到model中去。其他和提供的模板基本一致。
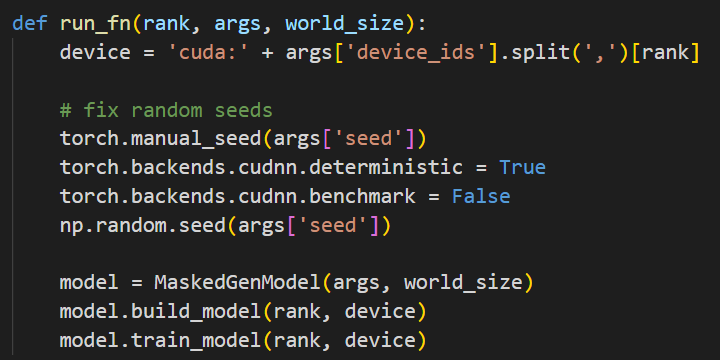
这种方法不用硬性指定可见的device,我觉得还不错,目前运行都没有问题。
另一个需要注意的问题就是在这种多GPU并行训练的情况下,我们save和load的checkpoint在哪个device上。默认情况下load会将模型加载到当初训练存储的device上,如果这个时候device有变化,需要指定新的GPU id。