🔗:https://leetcode.cn/problems/xu-lie-hua-er-cha-shu-lcof/
时隔一年再次刷到这道题,突然发现我根本没有完全搞懂,花了不少时间思考了一下这道题,我把心得记录下来。
核心思路
要想做到二叉树的序列化和反序列化,最核心的想法是保持序列化和反序列化的方法一致,解铃还需系铃人。如果按照构造二叉树的思路,只有两种遍历组合才能确定一棵二叉树,这显然不符合我们序列化的初衷。那么我们为什么能做到序列化二叉树呢?因为一般的遍历没有存储nullptr,通过存储nullptr的情况,任何遍历都可以作为序列化的方法,包括前序、中序、后序、层次遍历。
下面的写法都是前序遍历,因为我写的最直接。
序列化二叉树
序列化二叉树的代码如下:
void serial(TreeNode* root,string& res){
if(root==nullptr){
res+="#,";
return;
}
res+=to_string(root->val)+",";
serial(root->left,res);
serial(root->right,res);
}
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
string res;
serial(root,res);
return res;
}
这里有一些细节问题:
为什么我们一定要定义一个返回类型是
void的方法?如果直接用
string类型做返回类型,在root==nullptr时怎么进行判断呢?是返回还是不返回?这种需要反复退回栈状态需要void类型作为返回类型。分隔符的用法
不管是将分隔符放在后面还是前面,只要保证序列化与反序列化一致就可以,不用过于纠结。
nullptr的表示我这里用”#”来表示空指针,也可以用”null”或者其他方式,选择一个字符主要是考虑到反序列化时可以处理得简单点,但是基于C++的用法,不管是不是一个字符都需要自己根据分隔符来分,好像没有简单多少。
res+="#,"这个问题是我没想到的,发现了以后忽然很合理,同样的程序只是将
res+="#,"和res+=to_string(root->val)+","两个语句分开写成:res=res+"#"以及res=res+to_string(root->val)+","效率的差别竟然有这么大!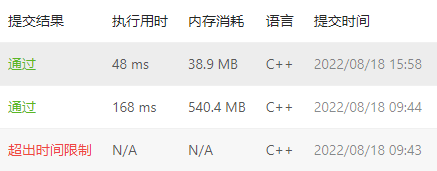
在都拆开写的情况下会超时!改一条语句就可以通过,将两条语句都改为
+=后效率终于看得过去了!仔细想来,对于类而言,
+=和拆开真的实现不同,如果拆开需要new一个新对象!而+=真的只是赋值!这个在今后的编程中也需要注意!
反序列化二叉树
序列化二叉树后我们可以看看我们序列化的结果:
1,2,#,#,3,4,#,#,5,#,#,
虽然看上去多了一个,,但是不足为惧。反序列化二叉树的代码如下:
TreeNode* deserial(list<string>& dataArray){
if(dataArray.front()=="#"){
dataArray.erase(dataArray.begin());
return nullptr;
}
TreeNode* root=new TreeNode(stoi(dataArray.front()));
dataArray.erase(dataArray.begin());
root->left=deserial(dataArray);
root->right=deserial(dataArray);
return root;
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
list<string> dataArray;
string str;
for(int i=0;i<data.length();i++){
if(data[i]==','){
dataArray.push_back(str);
str.clear();
}
else
str.push_back(data[i]);
}
if(!str.empty()){
dataArray.push_back(str);
str.clear();
}
return deserial(dataArray);
}
同样有很多细节问题:
我们为什么一定要定义一个
list?可以直接用data读取构造吗?直接用
data构造我试过,问题不在于读取本身,而是构造过程中,如果直接用data,当我们遇到nullptr的情况后需要return回上一个状态,而此时data本身还保持着上一个状态的值,也就是说data的第一个字符还是”#”!字符长度没有变少!如果我们想要在退回后还能保持新状态的data,那么我们就需要一个list!这个代码跟官方题解没区别,它用C++来split字符串的方法我觉得可以学习!很简洁好理解!