Transformer演变史
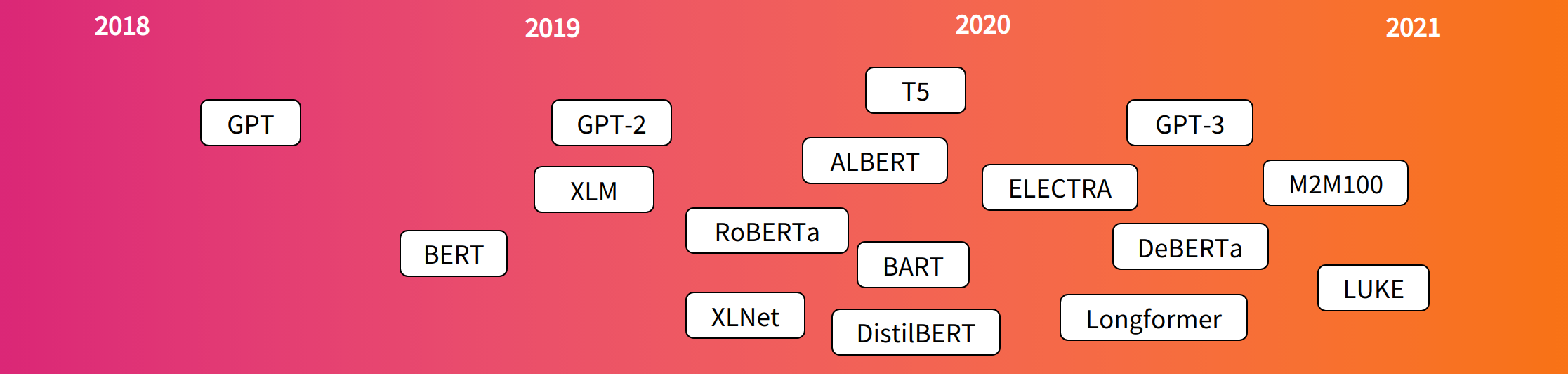
- 2017年6月:Transformer architecture, the focus of the original research was on translation tasks.
- 2018年6月:GPT, the first pretrained Transformer model, used for fine-tuning on various NLP tasks and obtained state-of-the-art results.
- 2018年10月:BERT, another large pretrained model, this one designed to produce better summaries of sentences.
- 2019年2月:GPT-2, an improved (and bigger) version of GPT that was not immediately publicly released due to ethical concerns.
- 2019年10月:DistillBERT, a distilled version of BERT that is 60% faster, 40% lighter in memory, and still retains 97% of BERT’s performance.
- 2019年10月:BART and T5, two large pretrained models using the same architecture as the original Transformer model (the first to do so).
- 2020年5月:GPT-3, , an even bigger version of GPT-2 that is able to perform well on a variety of tasks without the need for fine-tuning (called zero-shot learning).
以上只是一个不完整的介绍,这些模型大体可以分为三类:
- GPT-like(also called auto-regressive Transformer models)
- BERT-like(also called auto-encoding Transformer models)
- BART/T5-like(also called sequence-to-sequence Transformer models)
Transformers的共性
- 它们都是language models(self-supervised,不需要人工标注),通过transfer learning(迁移学习)需要再fine tune on a specific task.
- 它们都是大模型,训练的数据越大效果越好。下图是各个Transformer的参数大小:
- Encoder和Decoder:
- Encoder-only models:
- Use only the encoder of a Transformer model.
- The pretraining of these models usually revolves around somehow corrupting a given sentence (for instance, by masking random words in it) and tasking the model with finding or reconstructing the initial sentence.
- Best suited for tasks requiring an understanding of the full sentence, such as sentence classification, named entity recognition (and more generally word classification)
- BERT, ALBERT, DistillBERT, ELECTRA, RoBERTa
- Decoder-only models:
- Use only the decoder of a Transformer model.
- The pretraining of decoder models usually revolves around predicting the next word in the sentence.
- These models are best suited for tasks involving text generation
- CTRL, GPT, GPT-2, Transformer XL
- Encoder-decoder models or sequence-to-sequence models:
- Use both parts of the Transformer architecture.
- The pretraining of these models can be done using the objectives of encoder or decoder models, but usually involves something a bit more complex.
- Best suited for tasks revolving around generating new sentences depending on a given input, such as summarization, translation, or generative question answering
- BART, mBART, Marian, T5
- Encoder-only models:
| Model | Examples | Tasks |
|---|---|---|
| Encoder | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | Sentence classification, named entity recognition, extractive question answering |
| Decoder | CTRL, GPT, GPT-2, Transformer XL | Text generation |
| Encoder-decoder | BART, T5, Marian, mBART | Summarization, translation, generative question answering |
Bias and Limitations
When you use these tools, you therefore need to keep in the back of your mind that the original model you are using could very easily generate sexist, racist, or homophobic content. Fine-tuning the model on your data won’t make this intrinsic bias disappear.