本篇文章只记录Python与C++不相同需要注意的地方。
变量、运算符与数据类型
注释
# 这是单行注释
'''
这是多行
注释
'''
# 三个双引号有两个作用,一是注释多行,二是定义多行字符串,所以在这里运行会有输出
"""
这是多行注释,用三个双引号
这是多行注释,用三个双引号
这是多行注释,用三个双引号
"""
'\n这是多行注释,用三个双引号\n这是多行注释,用三个双引号 \n这是多行注释,用三个双引号\n'
变量和赋值
Python变量不需要定义和初始化,不需要指定类型
# 运行一下就好啦
set_1 = {"欢迎", "学习","Python"}
print(set_1.pop()) #为什么是Python?
Python
数据类型与转换
Python中的类型都是对象,有对应的方法和属性。需要查相应的文档。
#查看属性和方法
import decimal #decimal包
from decimal import Decimal #Decimal是decimal包里的对象
dir(decimal) #查看decimal包中的属性和方法,包也是对象
['BasicContext',
'Clamped',
'Context',
'ConversionSyntax',
'Decimal',
'DecimalException',
'DecimalTuple',
'DefaultContext',
'DivisionByZero',
'DivisionImpossible',
'DivisionUndefined',
'ExtendedContext',
'FloatOperation',
'HAVE_THREADS',
'Inexact',
'InvalidContext',
'InvalidOperation',
'MAX_EMAX',
'MAX_PREC',
'MIN_EMIN',
'MIN_ETINY',
'Overflow',
'ROUND_05UP',
'ROUND_CEILING',
'ROUND_DOWN',
'ROUND_FLOOR',
'ROUND_HALF_DOWN',
'ROUND_HALF_EVEN',
'ROUND_HALF_UP',
'ROUND_UP',
'Rounded',
'Subnormal',
'Underflow',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__libmpdec_version__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'__version__',
'getcontext',
'localcontext',
'setcontext']
a = decimal.getcontext() #getcontext()显示Decimal对象的精度prec,rounding等等
print(a)
Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, capitals=1, clamp=0, flags=[], traps=[InvalidOperation, DivisionByZero, Overflow])
decimal.getcontext().prec = 4 #可以通过调整prec,将精度调到4位
c = Decimal(1) / Decimal(3)
print(c)
0.3333
不可变类型
| 类型 | 名称 | 示例 |
|---|---|---|
| int | 整型 <class 'int'> | -876, 10 |
| float | 浮点型<class 'float'> | 3.149, 11.11 |
| bool | 布尔型<class 'bool'> | True, False |
#可以用bool()将其他类型转换为bool型
print(bool(0.00),bool(10.31)) #bool()作用在基本类型变量,只要不是0,转换为bool类型后就是True
print(bool(()),bool('python')) #bool()作用在容器类型变量,只要不是空,转换为bool类型后就是True
False True
False True
可变类型
获取类型信息
获取类型信息有两种方法:
type(object)isinstance(object, classinfo)
print(type(1))
print(isinstance(1,int))
<class 'int'>
True
type()不认为子类是一种父类类型,不考虑继承关系。isinstance()会认为子类是一种父类类型,考虑继承关系。
类型转换
print(int(520.52)) # int()转换为整型
print(float('520.52')) # float()转换为浮点型
print(str(10 + 10)) # str()转换为字符串
520
520.52
20
运算符
'''
和C++不同,/代表准确结果,//才是整除
'''
print(11/3)
print(11//3)
3.6666666666666665
3
# 幂运算
print(2**3)
8
位运算
| 操作符 | 名称 | 示例 |
|---|---|---|
~ | 按位取反 | ~4 |
& | 按位与 | 4 & 5 |
\| | 按位或 | 4 \| 5 |
^ | 按位异或 | 4 ^ 5 |
<< | 左移 | 4 << 2 |
>> | 右移 | 4 >> 2 |
# 三元操作符
x, y = 4, 5
small = x if x < y else y
print(small)
4
其他运算符
| 操作符 | 名称 | 示例 |
|---|---|---|
in | 存在 | 'A' in ['A', 'B', 'C'] |
not in | 不存在 | 'h' not in ['A', 'B', 'C'] |
is | 是 | "hello" is "hello" |
not is | 不是 | "hello" is not "hello" |
注意:
- 以上的运算符得到的结果是True或者False
- is, is not 对比的是两个变量的内存地址
- ==, != 对比的是两个变量的值
- 比较的两个变量,指向的都是地址不可变的类型(str等),那么is,is not 和 ==,!= 是完全等价的。
- 对比的两个变量,指向的是地址可变的类型(list,dict,tuple等),则两者是有区别的。
运算符的优先级:
- 一元运算符优于二元运算符,如正负号。
- 先算术运算,后移位运算,最后位运算。
- 逻辑运算最后结合
| 运算符 | 描述 |
|---|---|
| ** | 指数(最高优先级) |
| ~+- | 按位翻转,一元加号和减号 |
| * / % // | 乘,除,取模和取整除) |
| + - | 加法减法 |
| » « | 右移,左移运算符 |
| & | 位‘AND’ |
| ^| | 位运算符 |
| <=<»= | 比较运算符 |
| <>==!= | 等于运算符 |
| =%=/=//=-=+=*=**= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
print(-3 ** 2) # -9
print(3 ** -2) # 0.11111111111
print(-3 * 2 + 5 / -2 -4) # -12.5
print(3 < 4 and 4 < 5) # True
-9
0.1111111111111111
-12.5
True
打印
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
- 将对象以字符串表示的方式格式化输出到流文件对象file里。其中所有非关键字参数都按
str()方式进行转换为字符串输出; - 关键字参数
sep是实现分隔符,比如多个参数输出时想要输出中间的分隔字符; - 关键字参数
end是输出结束时的字符,默认是换行符\n; - 关键字参数
file是定义流输出的文件,可以是标准的系统输出sys.stdout,也可以重定义为别的文件; - 关键字参数
flush是立即把内容输出到流文件,不作缓存。
默认分隔符是空格,每次输出都会换行
shoplist = ['apple','mango','carrot','banana']
print("This is printed without 'end' and 'sep'.")
for item in shoplist:
print(item)
This is printed without 'end' and 'sep'.
apple
mango
carrot
banana
shoplist = ['apple','mango','carrot','banana']
print("This is printed with 'end='&''.")
for item in shoplist:
print(item, end='&')
This is printed with 'end='&''.
apple&mango&carrot&banana&
shoplist = ['apple','mango','carrot','banana']
print("This is printed with 'sep='&'.")
for item in shoplist:
print(item, 'another string', sep='&')
This is printed with 'sep='&'.
apple&another string
mango&another string
carrot&another string
banana&another string
位运算
位运算
| 操作符 | 名称 | 示例 |
|---|---|---|
~ | 按位取反 | ~4 |
& | 按位与 | 4 & 5 |
\| | 按位或 | 4 \| 5 |
^ | 按位异或 | 4 ^ 5 |
<< | 左移 | 4 << 2 |
>> | 右移 | 4 >> 2 |
利用位运算实现快速计算:
- 通过
<<,>>快速计算2的倍数问题
n << m #计算n*(2^m)
n >> m #计算n(2^m)
- 通过
^快速交换两个整数
#异或的性质:a^a=0,a^0=a
a ^= b # a=a^b:
b ^= a # b=b^a=b^(a^b)=a^(b^b)=a
a ^= b # a=a^b=(a^b)^a=b^(a^a)=b
- 通过
a & (-a)快速获取a的最后为1位置的整数(跟求补码取反加1同理)
00 00 01 01 -> 5
&
11 11 10 11 -> -5
---
00 00 00 01 -> 1
00 00 11 10 -> 14
&
11 11 00 10 -> -14
---
00 00 00 10 -> 2
利用位运算实现整数集合
一个数的二进制表示可以看作是一个集合(0 表示不在集合中,1 表示在集合中)。
比如集合 {1, 3, 4, 8},可以表示成 01 00 01 10 10 而对应的位运算也就可以看作是对集合进行的操作。(从低位到高位)
- 元素与集合的操作
a | (1<<i) -> 把 i 插入到集合中
a & ~(1<<i) -> 把 i 从集合中删除
a & (1<<i) -> 判断 i 是否属于该集合(零不属于,非零属于)
- 集合之间的操作
a 补 -> ~a
a 交 b -> a & b
a 并 b -> a | b
a 差 b -> a & (~b)
【例子】 Python 的bin() 输出。
print(bin(3)) # 0b11
print(bin(-3)) # -0b11
print(bin(-3 & 0xffffffff))
# 0b11111111111111111111111111111101
print(bin(0xfffffffd))
# 0b11111111111111111111111111111101
print(0xfffffffd) # 4294967293
0b11
-0b11
0b11111111111111111111111111111101
0b11111111111111111111111111111101
4294967293
- Python中
bin一个负数(十进制表示),输出的是它的原码的二进制表示加上个负号,巨坑。 - Python中的整型是补码形式存储的。
- Python中整型是不限制长度的不会超范围溢出。
所以为了获得负数(十进制表示)的补码,需要手动将其和十六进制数0xffffffff进行按位与操作,再交给bin()进行输出,得到的才是负数的补码表示。
条件语句
if语句
temp = input("猜一猜小姐姐想的是哪个数字?")
guess = int(temp) # input 函数将接收的任何数据类型都默认为 str。
if guess == 666:
print("你太了解小姐姐的心思了!")
print("哼,猜对也没有奖励!")
else:
print("猜错了,小姐姐现在心里想的是666!")
print("游戏结束,不玩儿啦!")
猜一猜小姐姐想的是哪个数字?2
猜错了,小姐姐现在心里想的是666!
游戏结束,不玩儿啦!
elif = else if,举例如下:
temp = input('请输入成绩:')
source = int(temp)
if 100 >= source >= 90:
print('A')
elif 90 > source >= 80:
print('B')
elif 80 > source >= 60:
print('C')
elif 60 > source >= 0:
print('D')
else:
print('输入错误!')
请输入成绩:100
A
assert
当assert后边的条件为False时,程序自动崩溃并抛出AssertionError异常。
在进行单元测试时,可以用来在程序中置入检查点,只有条件为True时才能让程序正常工作。
my_list = ['lsgogroup']
my_list.pop(0)
assert len(my_list) > 0
# AssertionError
循环语句
while循环
while后跟着str、list或其他任何序列,长度非零则视为真值。
string = 'abcd'
while string:
print(string)
string = string[1:]
# abcd
# bcd
# cd
# d
abcd
bcd
cd
d
while-else循环
while 布尔表达式:
代码块
else:
代码块
当while循环正常执行完的情况下,执行else输出,如果while循环中执行了跳出循环的语句,比如 break,将不执行else代码块的内容。
count = 0
while count < 5:
print("%d is less than 5" % count)
count = count + 1
else:
print("%d is not less than 5" % count)
# 0 is less than 5
# 1 is less than 5
# 2 is less than 5
# 3 is less than 5
# 4 is less than 5
# 5 is not less than 5
0 is less than 5
1 is less than 5
2 is less than 5
3 is less than 5
4 is less than 5
5 is not less than 5
count = 0
while count < 5:
print("%d is less than 5" % count)
count = 6
break
else:
print("%d is not less than 5" % count)
# 0 is less than 5
0 is less than 5
for循环
member = ['张三', '李四', '刘德华', '刘六', '周润发']
for each in member:
print(each)
# 张三
# 李四
# 刘德华
# 刘六
# 周润发
for i in range(len(member)):
print(member[i])
# 张三
# 李四
# 刘德华
# 刘六
# 周润发
张三
李四
刘德华
刘六
周润发
张三
李四
刘德华
刘六
周润发
dic = {'a':1,'b':2,'c':3,'d':4}
for key,value in dic.items():
print(key,value,sep=':',end=' ')
for key in dic.keys():
print(key,end=' ')
for value in dic.values():
print(value,end=' ')
a:1 b:2 c:3 d:4 a b c d 1 2 3 4
for-else循环
和while-else一样
for num in range(10,20): #range(10,20)表示[10,20)
for i in range(2,num):
if num%i == 0:
j = num / i
print('%d 等于 %d * %d' % (num,i,j))
break
else:
print(num,'是一个质数')
10 等于 2 * 5
11 是一个质数
12 等于 2 * 6
13 是一个质数
14 等于 2 * 7
15 等于 3 * 5
16 等于 2 * 8
17 是一个质数
18 等于 2 * 9
19 是一个质数
range函数
range([start,] stop[, step=1])
- 这个BIF(Built-in functions)有三个参数,其中用中括号括起来的两个表示这两个参数是可选的。只有stop是一定要写的。
step=1表示第三个参数的默认值是1。range这个BIF的作用是生成一个从start参数的值开始到stop参数的值结束的数字序列,该序列包含start的值但不包含stop的值。- 当start缺省的时候,默认从0开始。
for i in range(9):
print(i)
0
1
2
3
4
5
6
7
8
enumerate()函数
enumerate指枚举。
enumerate(sequence, [start=0])
- sequence:一个序列、迭代器或其他支持迭代对象。
- start:下标起始位置。给元素一个索引值,默认从0开始。
- 返回 enumerate(枚举) 对象
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
lst = list(enumerate(seasons))
print(lst)
lst = list(enumerate(seasons, start=1))
print(lst)
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
languages = ['Python','R','Matlab','C++']
for i, language in enumerate(languages, 2):
print(i, 'I love', language)
print('Done!')
2 I love Python
3 I love R
4 I love Matlab
5 I love C++
Done!
break语句
continue语句
continue终止本轮循环并开始下一轮循环。
for i in range(10):
if i % 2 != 0:
print(i)
continue
i += 2
print(i)
2
1
4
3
6
5
8
7
10
9
pass语句
pass 语句的意思是“不做任何事”,如果你在需要有语句的地方不写任何语句,那么解释器会提示出错,而 pass 语句就是用来解决这些问题的。 pass是空语句,不做任何操作,只起到占位的作用,其作用是为了保持程序结构的完整性。尽管pass语句不做任何操作,但如果暂时不确定要在一个位置放上什么样的代码,可以先放置一个pass语句,让代码可以正常运行。
def a_func():
File "<ipython-input-15-a2e1e12e0a2a>", line 1
def a_func():
^
SyntaxError: unexpected EOF while parsing
def a_func():
pass
推导式
列表推导式
[expr for value in collection [if condition]]
a = [(i,j) for i in range(0,3) if i < 1 for j in range(0,3) if j > 1]
print(a)
[(0, 2)]
支持多层嵌套
[m+'_'+n for m in ['a','b'] for n in ['c','d']]
['a_c', 'a_d', 'b_c', 'b_d']
元组表达式
(expr for value in collection [if condition])
a = (x for x in range(10))
print(a)
print(tuple(a))
<generator object <genexpr> at 0x7fb094664cf0>
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
字典推导式
{key_expr: value_expr for value in collection[if condition]}
b = {i: i%2 == 0 for i in range(10) if i % 3 == 0}
print(b)
{0: True, 3: False, 6: True, 9: False}
集合推导式
{expr for value in collection [if condition]}
c = {i for i in [1,2,3,4,5,5,6,4,3,2,1]}
print(c)
{1, 2, 3, 4, 5, 6}
其他
e = (i for i in range(10))
print(e)
'''
next(iterator[, default])
Return the next item from the iterator.
If default is given and the iterator is exhausted, it is returned instead of raising StopIteration.
'''
print(next(e))
print(next(e))
for each in e:
print(each, end=' ')
<generator object <genexpr> at 0x7fb094d949e0>
0
1
2 3 4 5 6 7 8 9
异常处理
Python标准异常总结
- BaseException:所有异常的 基类
- Exception:常规异常的 基类
- StandardError:所有的内建标准异常的基类
- ArithmeticError:所有数值计算异常的基类
- FloatingPointError:浮点计算异常
- OverflowError:数值运算超出最大限制
- ZeroDivisionError:除数为零
- AssertionError:断言语句(assert)失败
- AttributeError:尝试访问未知的对象属性
- EOFError:没有内建输入,到达EOF标记
- EnvironmentError:操作系统异常的基类
- IOError:输入/输出操作失败
- OSError:操作系统产生的异常(例如打开一个不存在的文件)
- WindowsError:系统调用失败
- ImportError:导入模块失败的时候
- KeyboardInterrupt:用户中断执行
- LookupError:无效数据查询的基类
- IndexError:索引超出序列的范围
- KeyError:字典中查找一个不存在的关键字
- MemoryError:内存溢出(可通过删除对象释放内存)
- NameError:尝试访问一个不存在的变量
- UnboundLocalError:访问未初始化的本地变量
- ReferenceError:弱引用试图访问已经垃圾回收了的对象
- RuntimeError:一般的运行时异常
- NotImplementedError:尚未实现的方法
- SyntaxError:语法错误导致的异常
- IndentationError:缩进错误导致的异常
- TabError:Tab和空格混用
- SystemError:一般的解释器系统异常
- TypeError:不同类型间的无效操作
- ValueError:传入无效的参数
- UnicodeError:Unicode相关的异常
- UnicodeDecodeError:Unicode解码时的异常
- UnicodeEncodeError:Unicode编码错误导致的异常
- UnicodeTranslateError:Unicode转换错误导致的异常
异常体系内部有层次关系,Python异常体系中的部分关系如下所示:
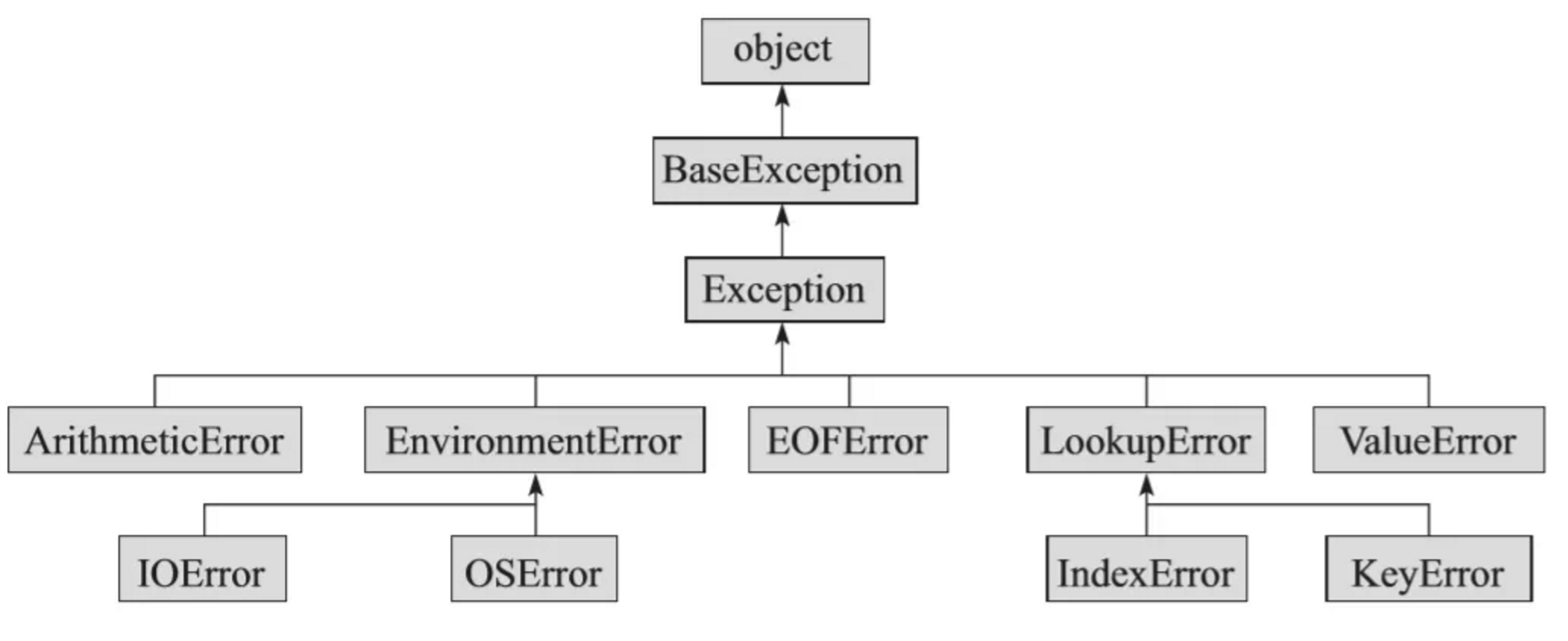
Python标准警告总结
- Warning:警告的基类
- DeprecationWarning:关于被弃用的特征的警告
- FutureWarning:关于构造将来语义会有改变的警告
- UserWarning:用户代码生成的警告
- PendingDeprecationWarning:关于特性将会被废弃的警告
- RuntimeWarning:可疑的运行时行为(runtime behavior)的警告
- SyntaxWarning:可疑语法的警告
- ImportWarning:用于在导入模块过程中触发的警告
- UnicodeWarning:与Unicode相关的警告
- BytesWarning:与字节或字节码相关的警告
- ResourceWarning:与资源使用相关的警告
try-except 语句
try:
检测范围
except Exception[as reason]:
出现异常后的处理代码
try 语句按照如下方式工作:
- 首先,执行
try子句(在关键字try和关键字except之间的语句) - 如果没有异常发生,忽略
except子句,try子句执行后结束。 - 如果在执行
try子句的过程中发生了异常,那么try子句余下的部分将被忽略。如果异常的类型和except之后的名称相符,那么对应的except子句将被执行。最后执行try - except语句之后的代码。 - 如果一个异常没有与任何的
except匹配,那么这个异常将会传递给上层的try中。
dict1 = {'a': 1, 'b': 2, 'v': 22}
try:
x = dict1['y']
except LookupError:
print('查询错误')
except keyError:
print('键错误')
else:
print(x)
查询错误
try-except-else语句尝试查询不在dict中的键值对,从而引发了异常。这一异常准确地说应属于KeyError,但由于KeyError是LookupError的子类,且将LookupError置于KeyError之前,因此程序优先执行该except代码块。所以,使用多个except代码块时,必须坚持对其规范排序,要从最具针对性的异常到最通用的异常。
一个 except 子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组。
try:
s = 1 + '1'
int('abc')
f = open('test.txt')
print(f.read())
f.close()
except (OSError, TypeError, ValueError) as error:
print('出错了!\n原因是:' + str(error))
出错了!
原因是:unsupported operand type(s) for +: 'int' and 'str'
try-except-finally 语句
try:
检测范围
except Exception[as reason]:
出现异常后的处理代码
finally:
无论如何都会被执行的代码
不管try子句里面有没有发生异常,finally子句都会执行。 如果一个异常在try子句里被抛出,而又没有任何的except把它截住,那么这个异常会在finally子句执行后被抛出。
def divide(x, y):
try:
result = x / y
print("result is", result)
except ZeroDivisionError:
print("division by zero!")
finally:
print("executing finally clause")
divide(2,1)
divide(2,0)
result is 2.0
executing finally clause
division by zero!
executing finally clause
try-except-else 语句
try:
检测范围
except(Exception1[, Exception2[,...ExceptionN]]]):
发生以上多个异常中的一个,执行这块代码
else:
如果没有异常执行这块代码
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print("Error: 没有找到文件或读取文件失败")
else:
print("内容写入文件成功")
fh.close()
内容写入文件成功
raise语句
Python 使用raise语句抛出一个指定的异常。
try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
An exception flew by!
文档信息
- 本文作者:weownthenight
- 本文链接:https://weownthenight.github.io/2021/04/16/Python%E5%9F%BA%E7%A1%80%E5%AD%A6%E4%B9%A0-%E4%B8%80/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)